최근 우연히 한빛미디어에서 제공하는 혼공학습단(링크) 모집 공고를 보게 되었는데, 흥미로워서 신청하게 되었습니다.
아래 커리큘럼에 따라 6주 만에 책 한 권을 완주해야 합니다.
음.. 아무래도 강제적으로 실습 내용을 블로그에 정리해야 하기 때문에, 잘 따라가기만 하면 6주 만에 책 한 권을 완독할 수 있다는 장점이 있습니다.
내용 정리
- 지도 학습: 정답(타깃)이 있으니 알고리즘이 정답을 맞히는 것을 학습
- 비지도 학습: 알고리즘은 타깃 없이 입력 데이터만 사용하며, 이런 종류의 알고리즘은 정답을 사용하지 않으므로 무언가를 맞힐 수가 없음. 대신 데이터를 잘 파악하거나 변형하는데 도움을 줌
- 강화 학습: 타깃이 아니라 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습(이 책에서는 다루지 않음..)
실습내용
Chapter01
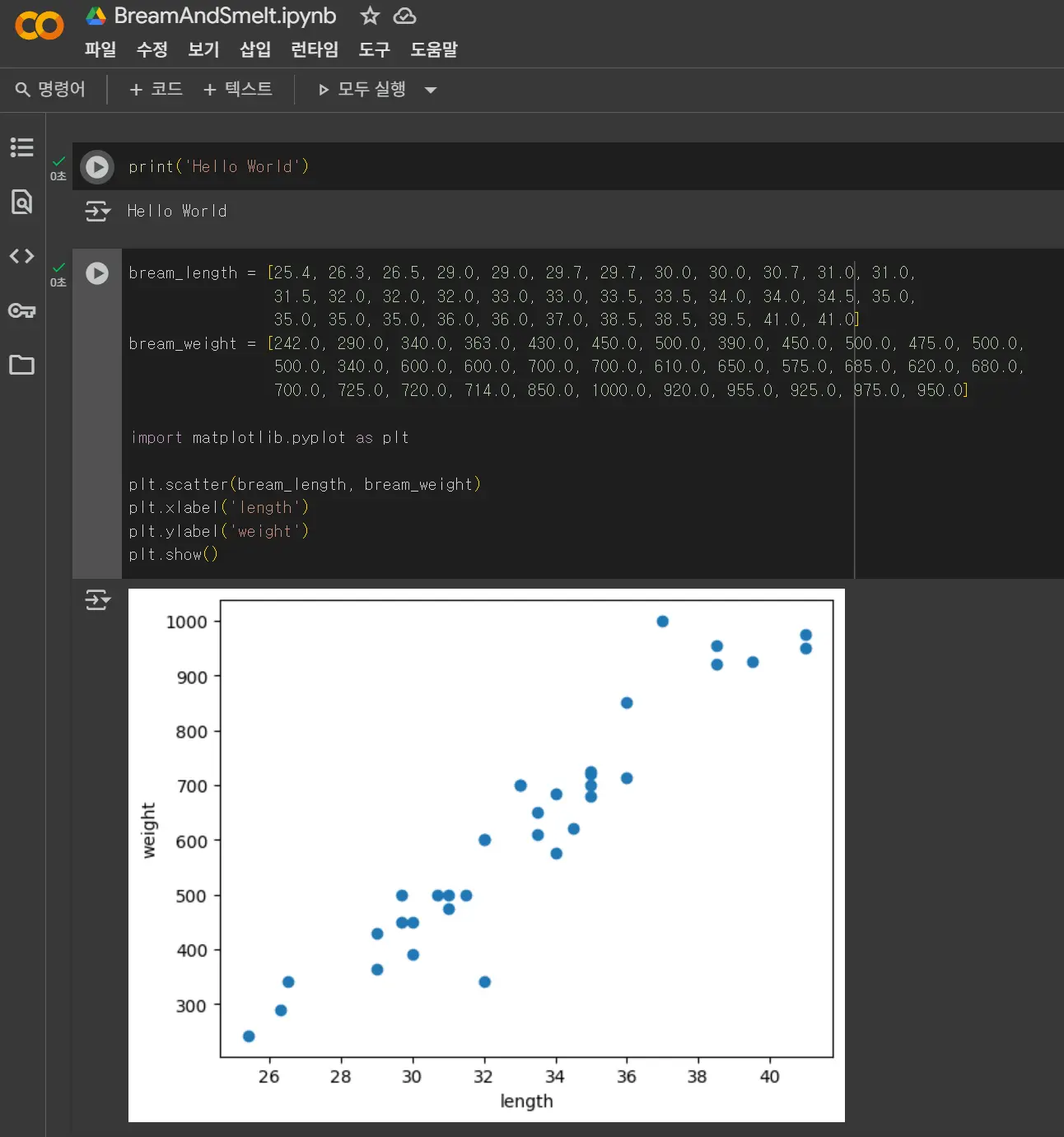
간단하게 데이터를 차트로 표시하는 것 같네요.
matplotlib 라이브러리를 통해 데이터를 시각화해서 볼 수 있습니다.

생선의 길이와 무게를 하나의 배열을 가진 2차원 리스트 생성합니다.
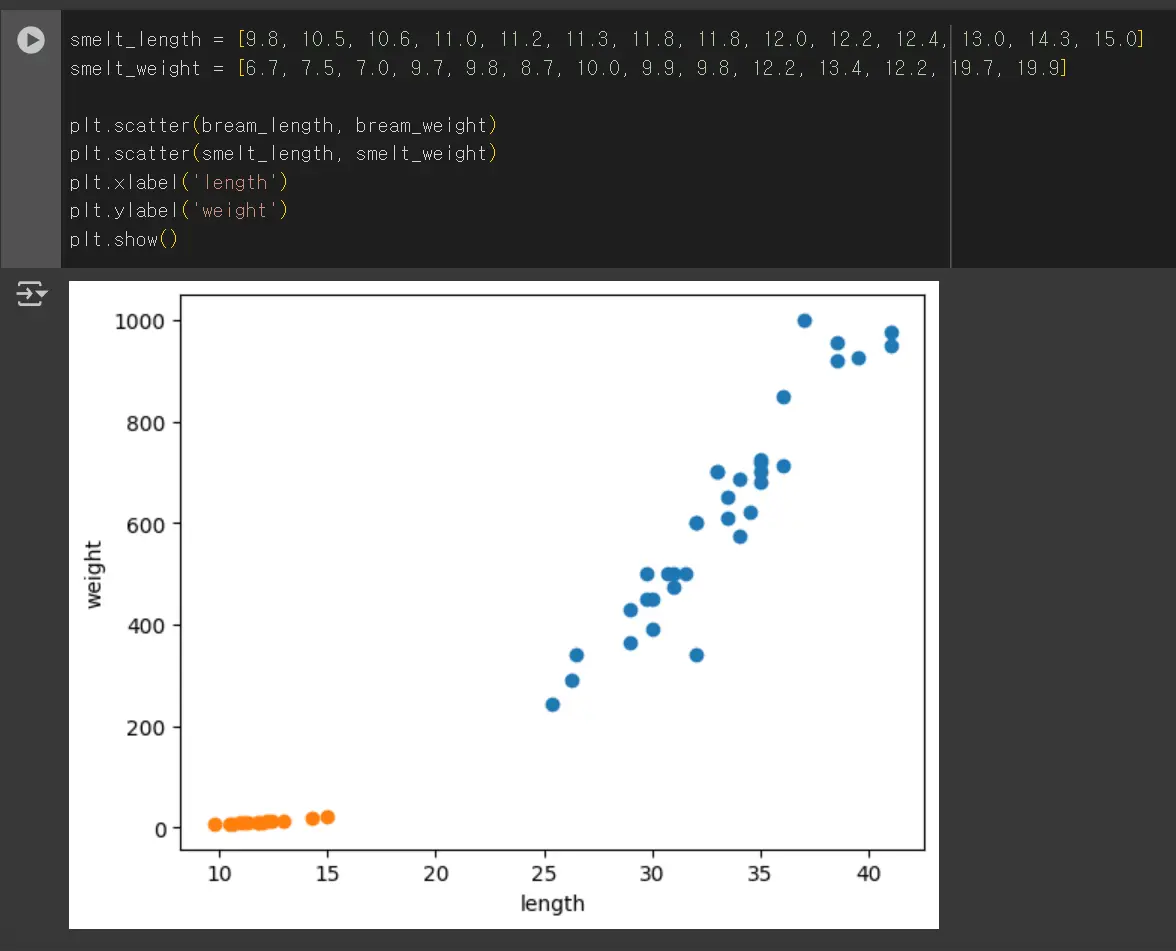
이밖에도 참고데이터를 판단하는 라이브러리로 새로운 데이터가 도미인지 빙어인지 맞출 수 있는 실습을 진행합니다.
Chapter02
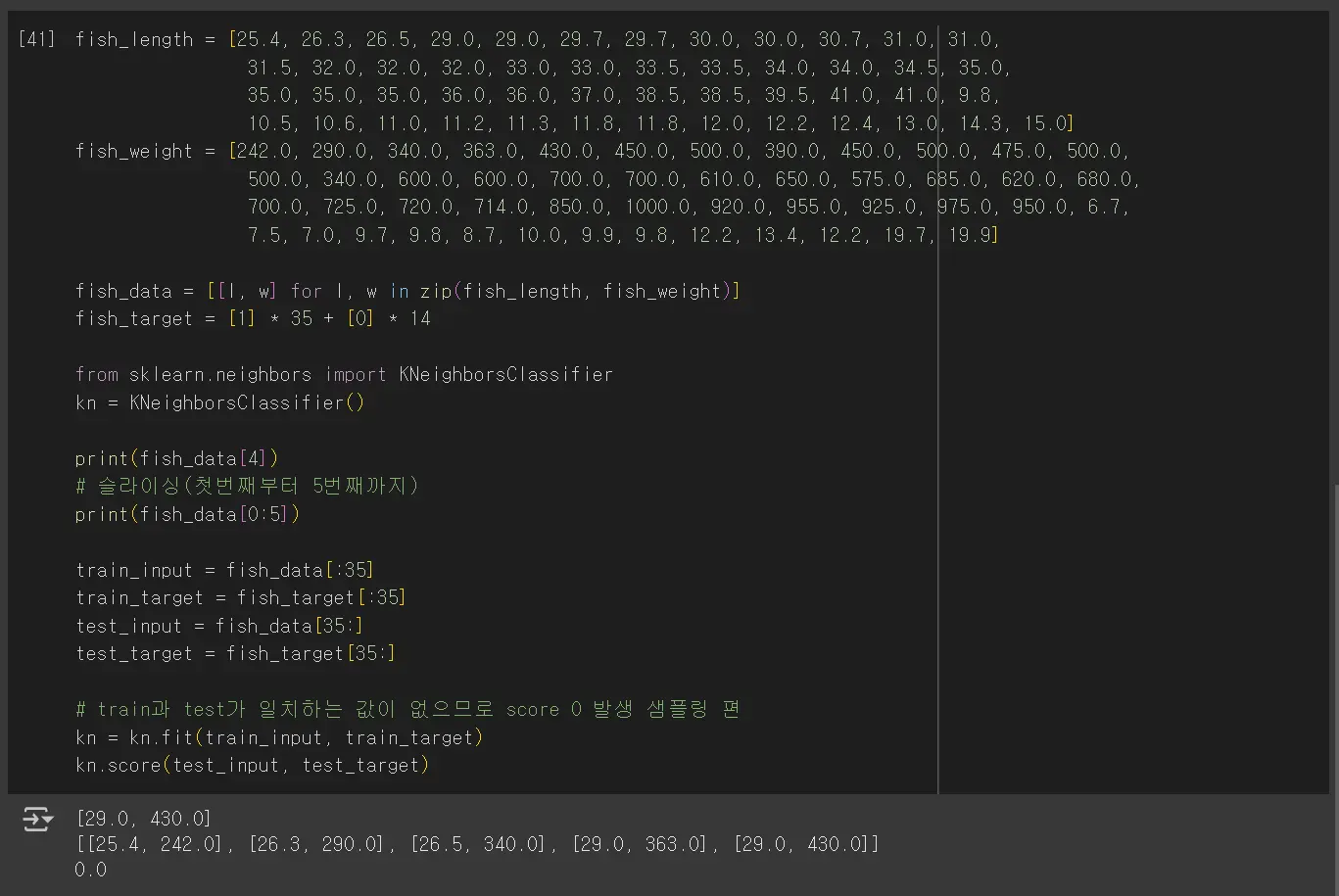
훈련 세트와 테스트 세트에 대해 학습합니다.
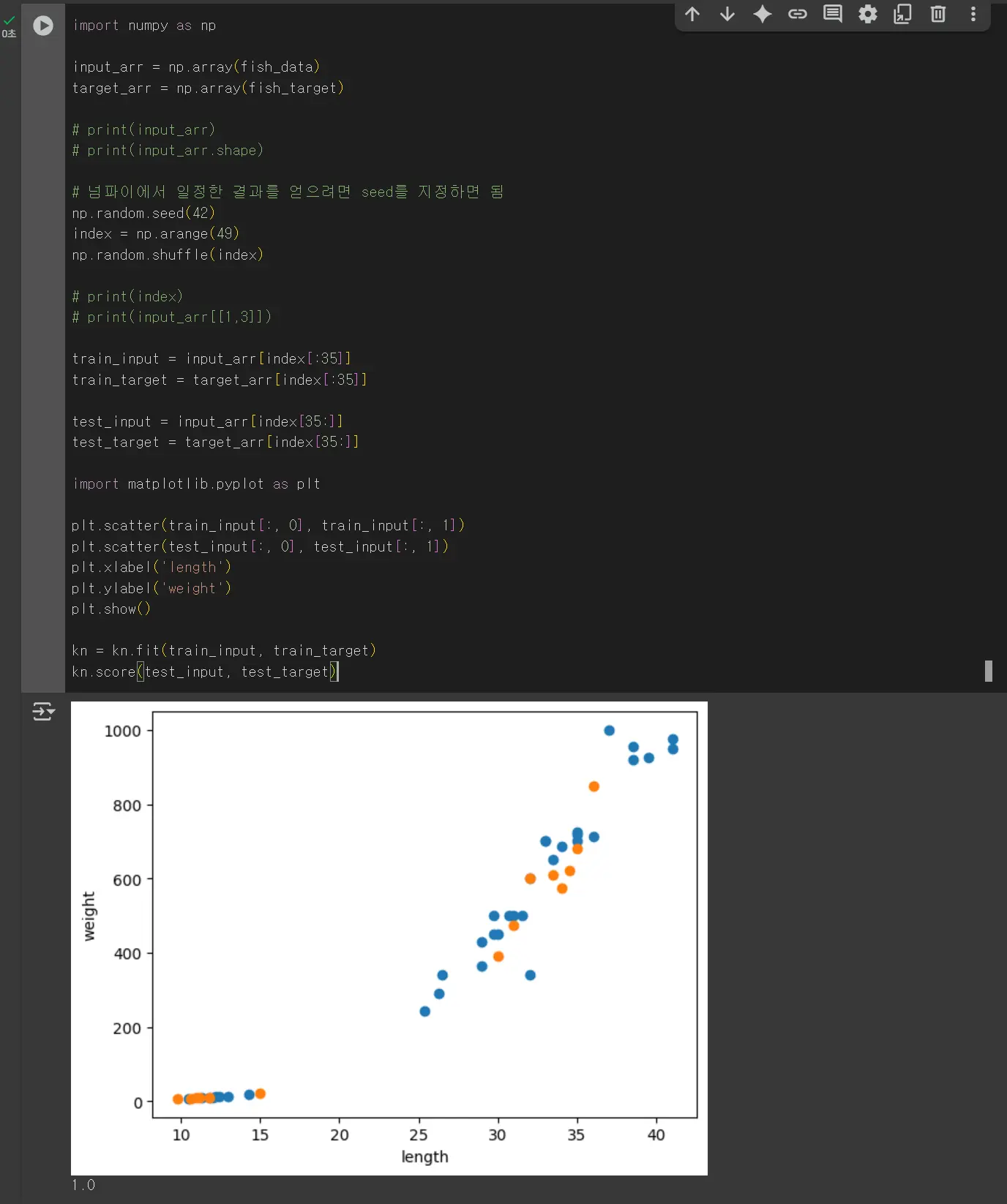
샘플링 편향을 없애기 위해 훈련 세트와 테스트 세트에 모두 도미와 빙어 정보를 넣는 작업을 실습합니다.
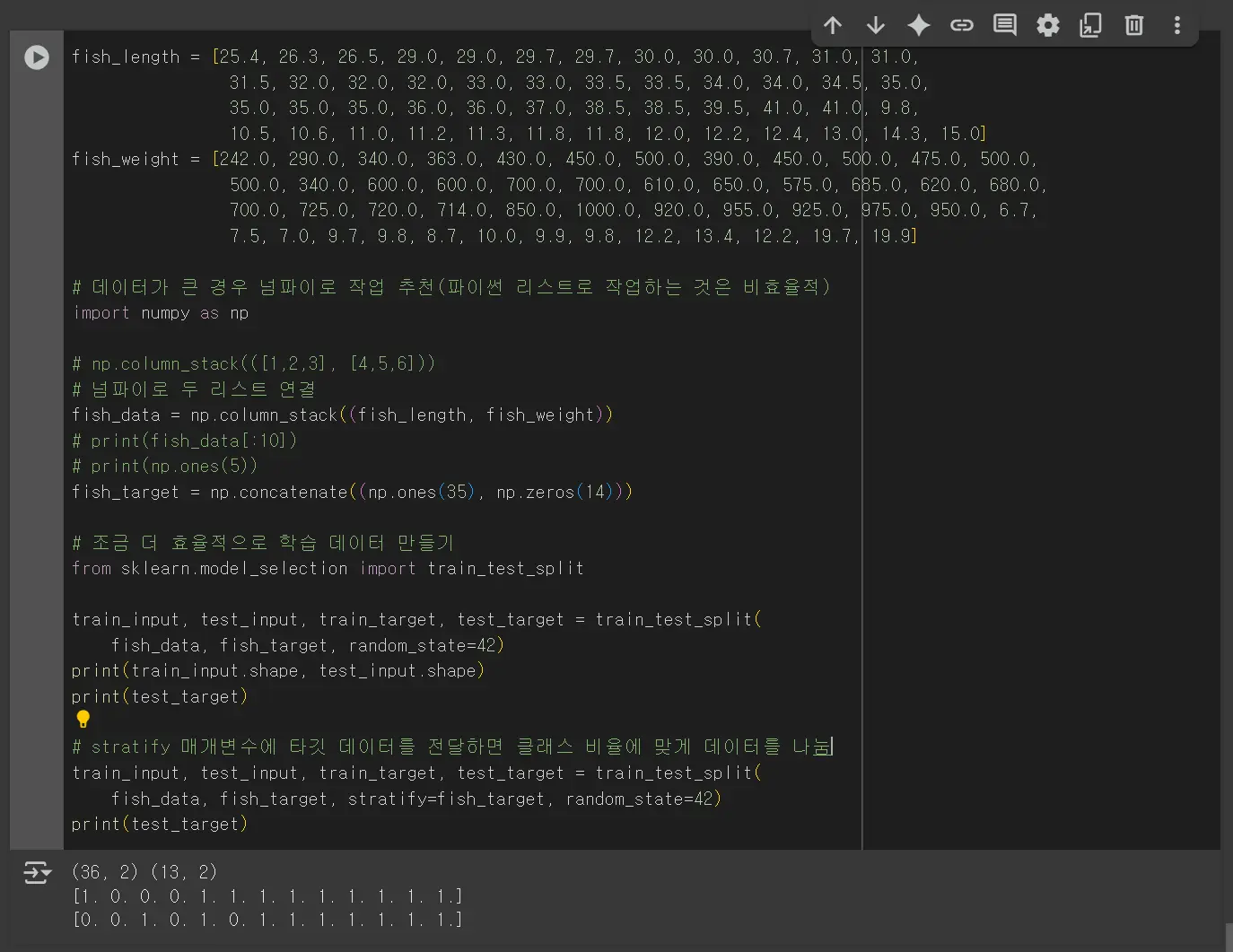
넘파이를 활용하여 샘플링 편향이 발생하지 않은 학습 데이터를 생성합니다.
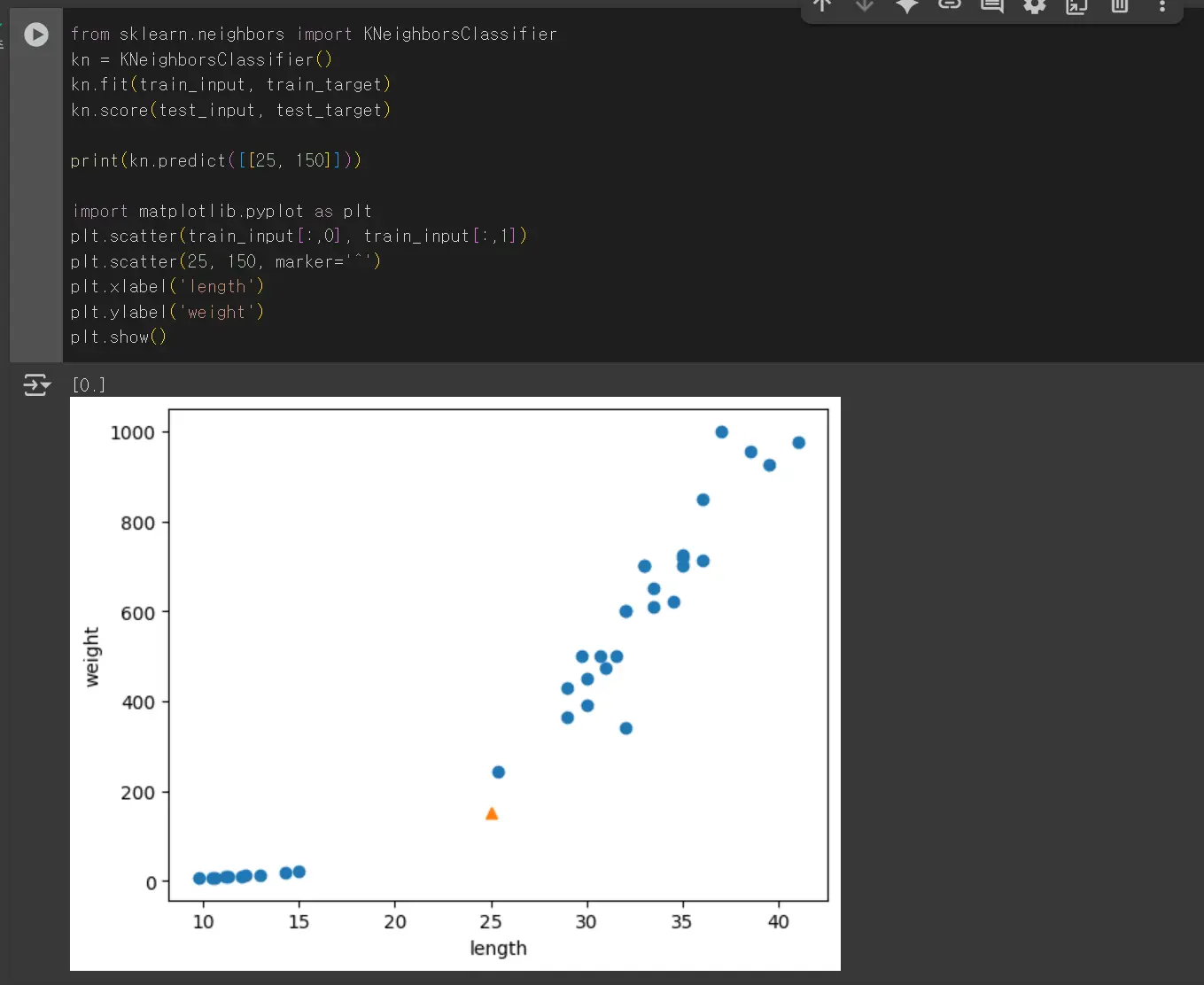
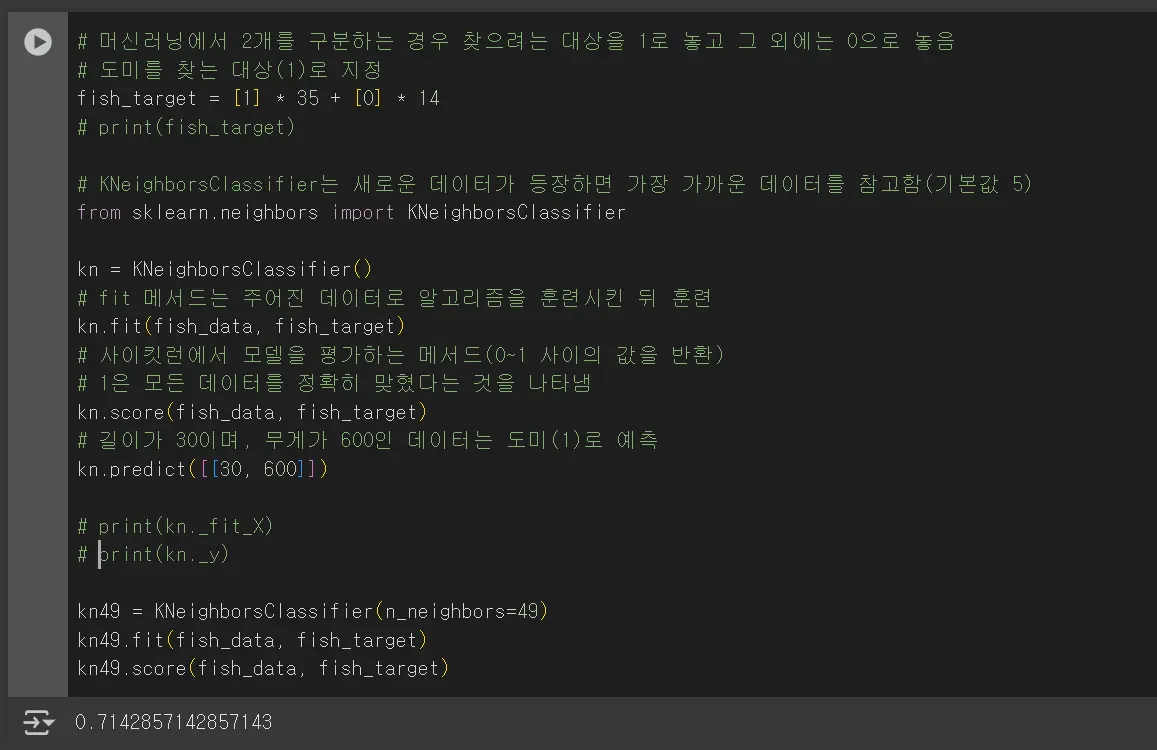
KNeighborsClassifier 클래스는 주어진 샘플에서 가장 가까운 5개의 이웃을 반환하는데 해당 데이터에서는 빙어가 더 많이 검출돼서 빙어(0)로 결과를 예측합니다.
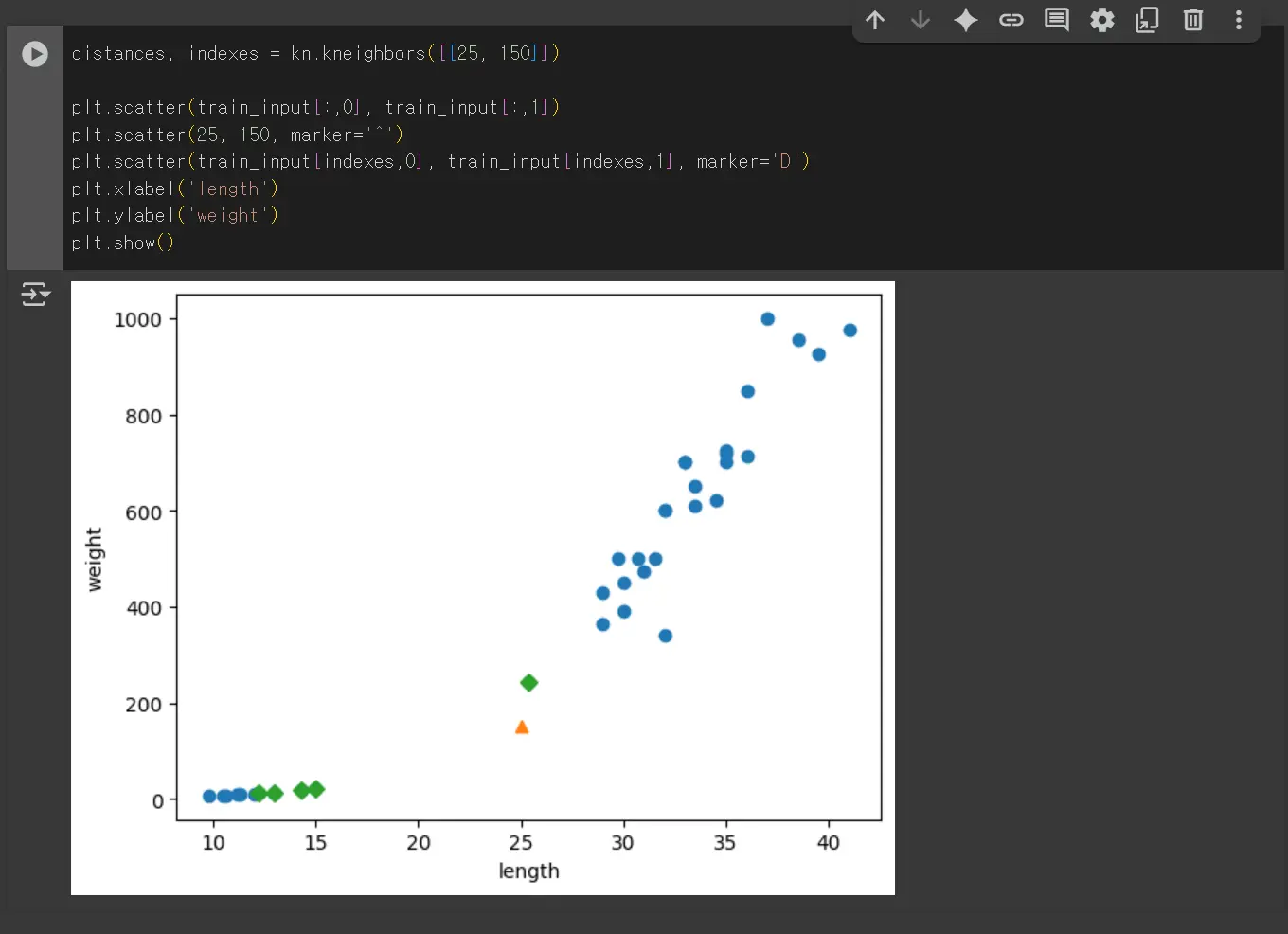
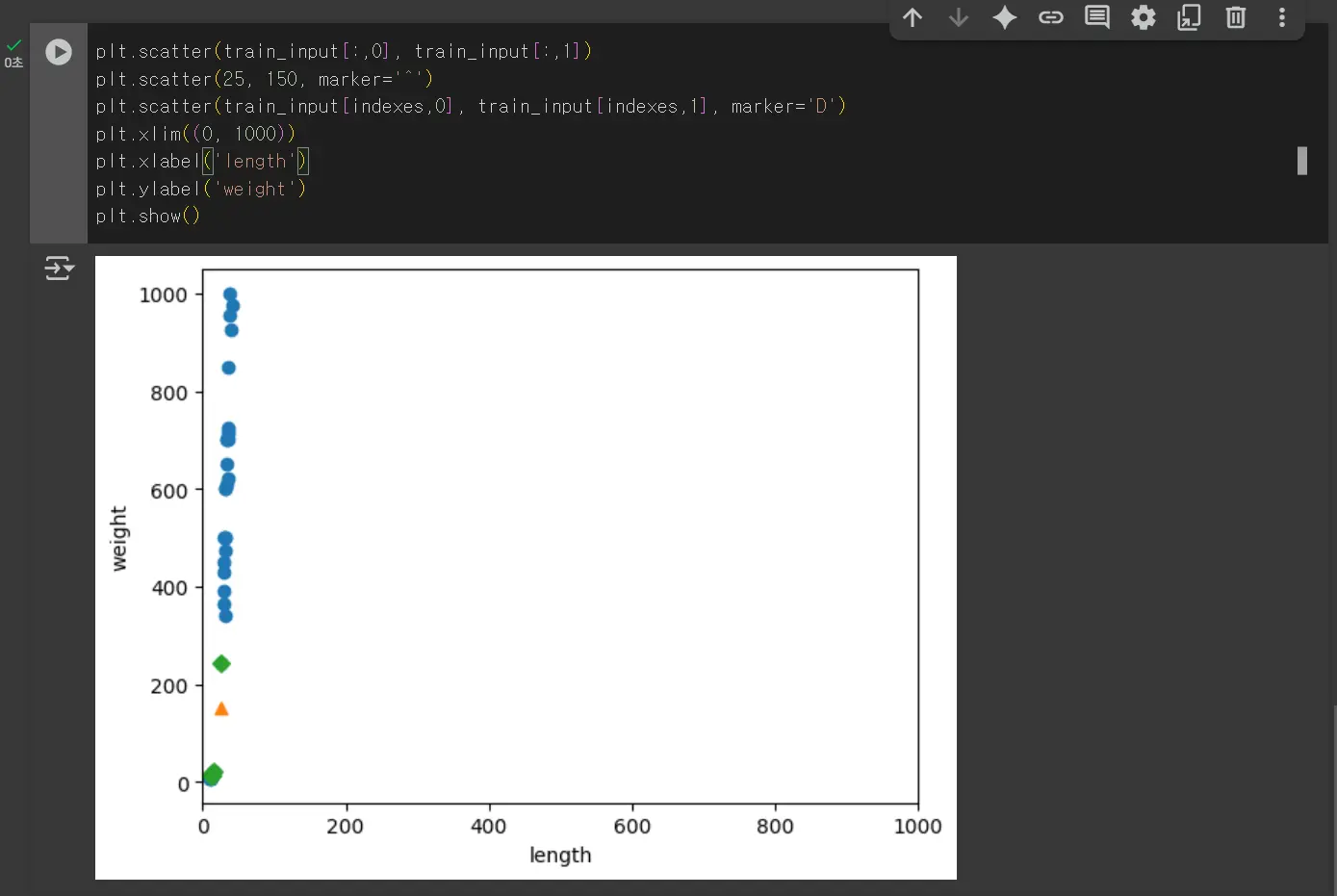
위와 같이 빙어가 4개 더 많이 걸립니다. 위와 같이 데이터를 표현하는 기준이 다른 경우는 알고리즘이 올바르게 예측할 수 없습니다. 데이터 전처리가 필요합니다.
분산은 데이터에서 평균을 뺀 값을 모두 제곱한 다음 평균을 내어 구합니다.
표준편차는 분산의 제곱근으로 데이터가 분산된 정도를 나타냅니다.
표준점수는 각 데이터가 원점에서 몇 표준편차만큼 떨어져 있는지를 나타내는 값입니다.
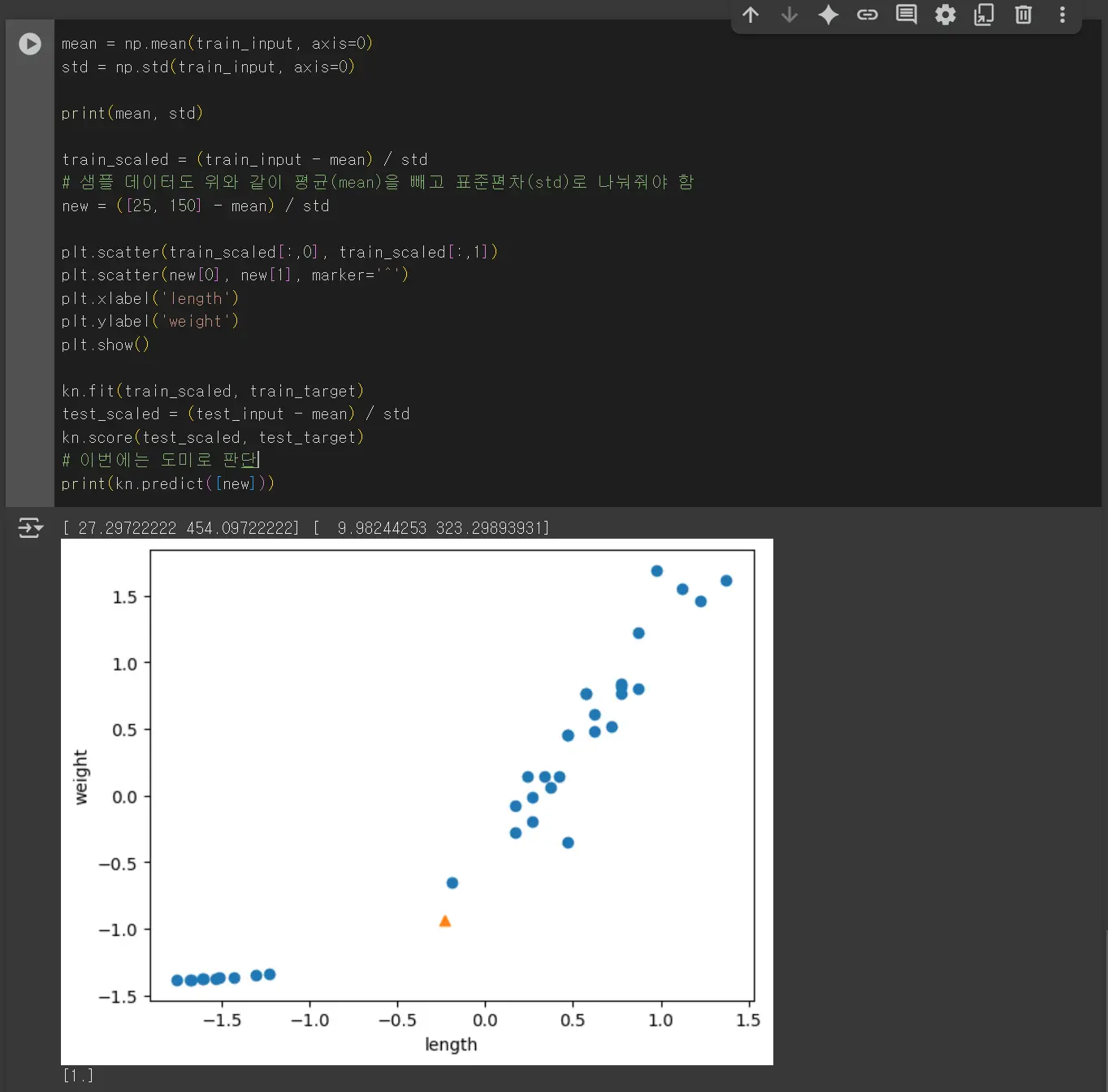
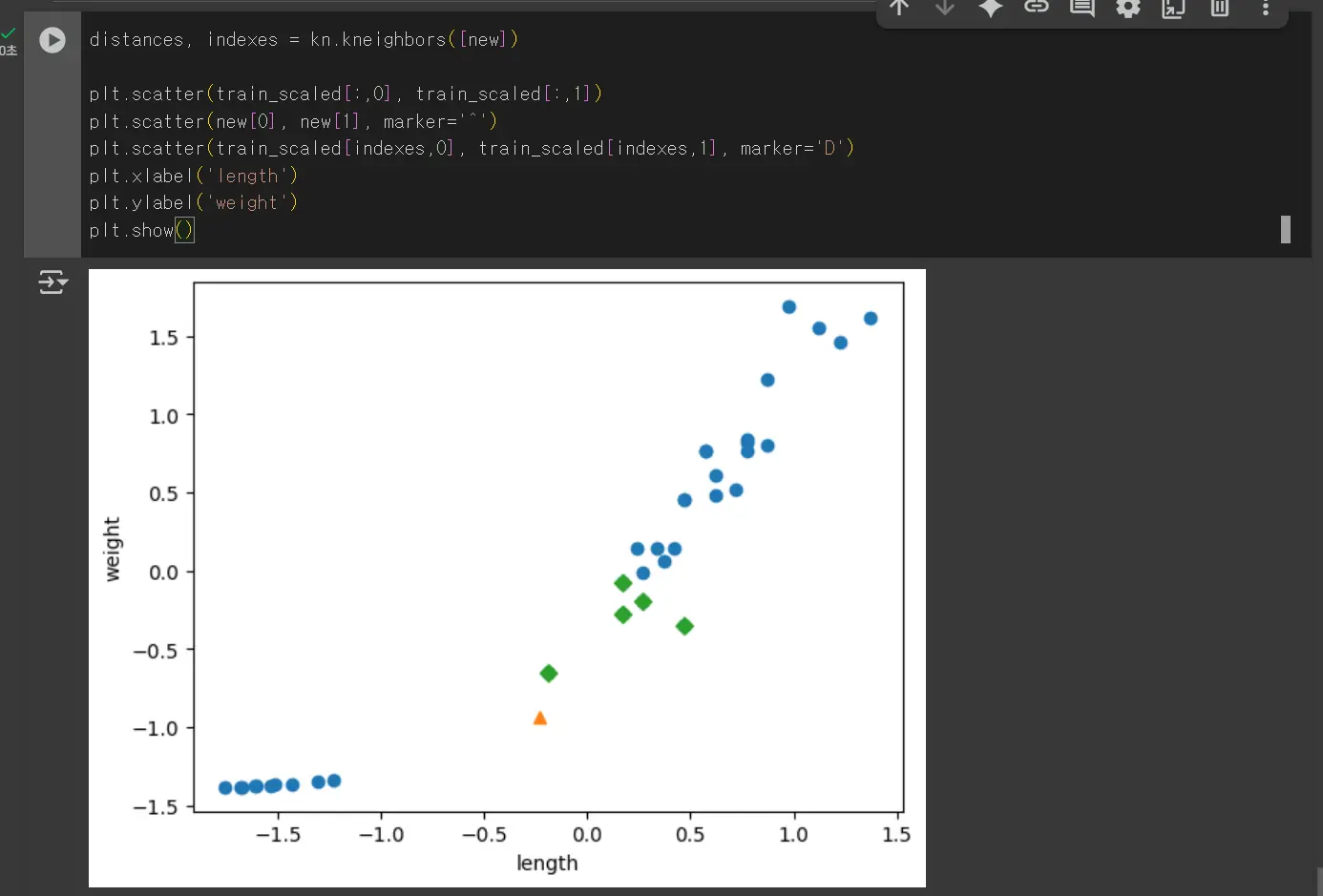
위와 같이 데이터 전처리를 거치면 샘플 값의 정보를 제대로 알 수 있습니다.
순서대로 하니 큰 문제 없이 챕터 2장까지는 해결할 수 있었네요..!